Can I run Direct3D12 on my system?
Without buying 3DMark (cheapest is Advanced Edition at $24.95), you won't get the DX12 call overhead comparison test. It's also a massive download and I really just want to find out if I could run DX12 on my system!
Essentially, I wanted a Direct3D12 test / sample app that has been compiled into an executable that I could just run. Google didn't turn up anything so I decided it's easier if I compiled one myself from the SharpDX 3.0.0 alpha 2 Direct3D12 Hello World example.
So here it is.
Dx12Test requires .NET Framework 4.5. You can give it a parameter from command line to pick which adapter to initialize (0=primary (default), 1=secondary...). If your GPU doesn't support DX12, you'll get a cryptic (it's just saying it's failed to initialize DX12) error message upon starting up.
Enjoy!
Tuesday, August 11, 2015
Wednesday, July 8, 2015
23.976 Judder
Preface
I remember spending countless hours trying to get my graphics card to hit exactly 23.976Hz when I first got involved in the HTPC scene years ago but only to find out you need to compensate for audio clock deviations as well. So the whole experiment starts all over again. These are the countless hours I'd never get back and I hope by writing this little post I'll save you the same trouble (and potentially lots of hours of your life).
The Problem
When you play 23.976 fps materials on a 60Hz display, you get what's called a "2:3 pulldown". Frames have to be played unevenly and we all know that. MPDN (Media Player .NET) has a feature called Fluid Motion that will get rid of the judder at the expense of clarity so it's generally advisable not to enable it if your display supports 23.976Hz refresh rate. In fact, MPDN's Fluid Motion is disabled by default if the display refresh rate is the same as (or a multiple of - more on that later) your video frame rate.
This is where the problem lies. It is terribly hard to get your graphics card to output the refresh rate you want and you often have to spend a lot of time tinkering with the custom refresh rates to get it right. You also have to take into account of the fact that video is played back at the speed of the audio (you get lip-sync problem otherwise) and not your system clock. MPDN calls this the reference clock.
What this means is you can't simply target 23.976Hz - you have to target 23.976Hz +/- ref clock. So even if your graphics card does 23.976Hz exactly out of the box, you'll still have the same rate mismatch (unless your reference clock is exactly 0%). Once you've corrected the mismatch for 23.976Hz, you have 24Hz, 30Hz, 50Hz, and 60Hz all requiring the same tedious corrections. Ref clock also changes with time and only gets more accurate the longer you let it play continuously - so you usually have to spend 5-10 minutes to find out if you've got the new settings right.
All of that assuming you know how to calculate your target refresh rate (video frame rate + ref clock deviation) in the first place and from what I've seen in the forum, most people don't.
The Solution
ReClock was the solution for a lot of people back in the days (myself included) but as we moved to 64-bit, ReClock is still firmly stuck in the 32-bit land. Since SlySoft (the creator of ReClock) have no plans to work on a 64-bit version, an alternative was clearly required. In fact, it is one of the most requested feature for MPDN for quite some time now (mostly via PMs).
Rather than trying to get the display to match our video, why not get the video to match the display instead? We do it for resolution (i.e. scaling) so why not do the same for refresh rate? Rate Tuner was thus created and comes with a calculator that automatically matches your video to your display refresh rate. Rate Tuner serves as a ReClock replacement and has the added benefit of it being fully integrated into MPDN.
Visit MPDN Extensions Wiki for more information about Rate Tuner.
I remember spending countless hours trying to get my graphics card to hit exactly 23.976Hz when I first got involved in the HTPC scene years ago but only to find out you need to compensate for audio clock deviations as well. So the whole experiment starts all over again. These are the countless hours I'd never get back and I hope by writing this little post I'll save you the same trouble (and potentially lots of hours of your life).
The Problem
When you play 23.976 fps materials on a 60Hz display, you get what's called a "2:3 pulldown". Frames have to be played unevenly and we all know that. MPDN (Media Player .NET) has a feature called Fluid Motion that will get rid of the judder at the expense of clarity so it's generally advisable not to enable it if your display supports 23.976Hz refresh rate. In fact, MPDN's Fluid Motion is disabled by default if the display refresh rate is the same as (or a multiple of - more on that later) your video frame rate.
This is where the problem lies. It is terribly hard to get your graphics card to output the refresh rate you want and you often have to spend a lot of time tinkering with the custom refresh rates to get it right. You also have to take into account of the fact that video is played back at the speed of the audio (you get lip-sync problem otherwise) and not your system clock. MPDN calls this the reference clock.
What this means is you can't simply target 23.976Hz - you have to target 23.976Hz +/- ref clock. So even if your graphics card does 23.976Hz exactly out of the box, you'll still have the same rate mismatch (unless your reference clock is exactly 0%). Once you've corrected the mismatch for 23.976Hz, you have 24Hz, 30Hz, 50Hz, and 60Hz all requiring the same tedious corrections. Ref clock also changes with time and only gets more accurate the longer you let it play continuously - so you usually have to spend 5-10 minutes to find out if you've got the new settings right.
All of that assuming you know how to calculate your target refresh rate (video frame rate + ref clock deviation) in the first place and from what I've seen in the forum, most people don't.
The Solution
ReClock was the solution for a lot of people back in the days (myself included) but as we moved to 64-bit, ReClock is still firmly stuck in the 32-bit land. Since SlySoft (the creator of ReClock) have no plans to work on a 64-bit version, an alternative was clearly required. In fact, it is one of the most requested feature for MPDN for quite some time now (mostly via PMs).
Rather than trying to get the display to match our video, why not get the video to match the display instead? We do it for resolution (i.e. scaling) so why not do the same for refresh rate? Rate Tuner was thus created and comes with a calculator that automatically matches your video to your display refresh rate. Rate Tuner serves as a ReClock replacement and has the added benefit of it being fully integrated into MPDN.
Visit MPDN Extensions Wiki for more information about Rate Tuner.
Tuesday, September 9, 2014
State of Legacy Drivers 2014: AMD vs NVIDIA
Preface
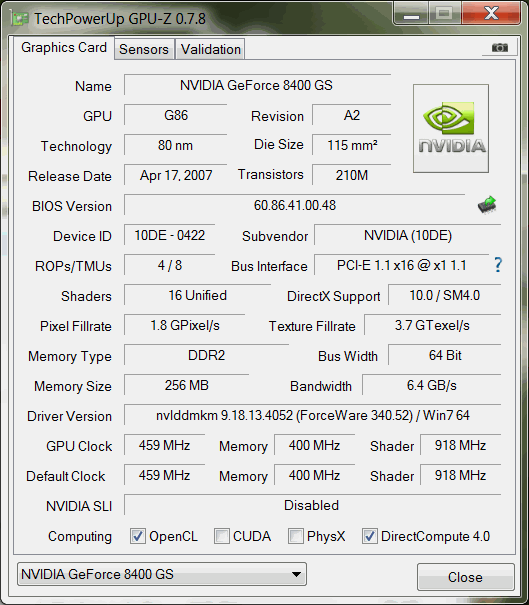
While they are both categorically in the legacy cards section of their respective manufacturers as of the date of this post, the cards I have do not provide for a completely fair comparison: ATI (AMD) HD 4350 (PCIe x16) vs NVIDIA 8400GS (PCIe x1).
The AMD card (GPU release date 30 Sep 2008) is one generation ahead of the NVIDIA one (17 Apr 2007). Not only that, the 8400GS is handicapped by its PCI-E x1 1.1 bus interface (HD 4350 has a PCI-E x16 2.0 interface). Everything hence shows that the AMD card is way superior, and it truly is.
| AMD HD 4350 | NVIDIA 8400GS | |
|---|---|---|
| Technology | 55nm | 80nm |
| Release Date | Sep 30, 2008 | Apr 17, 2007 |
| Transistors | 242M | 210M |
| Bus Interface | PCI-E 2.0 x16 @ x16 2.0 | PCI-E 1.1 x16 @ x1 1.1 |
| Memory Size | 512 MB | 256 MB |
| DirectX Support | 10.1 / SM4.1 | 10.0 / SM4.0 |

Drivers - Availability
Knowing that the AMD is a superior card, how does its drivers compare with NVIDIA's? A graphics card cannot function without its drivers after all.
With the 8400GS, it was as easy to install drivers as it is for the latest NVIDIA graphics cards - GeForce drivers 340.52 thus installed without a fuss. AMD have have dropped the HD 4350 drivers from the latest drivers distribution. It directed me to its legacy drivers page and the latest version happens to be 13.4 BETA! A quick Google search seems to suggest that 13.9 is simply the WHQL'd version of 13.4. So I downloaded v13.9 and installed it. All good so far.
Drivers - Quality
I'm basing my assessment off a Direct3D 9 Shader Model 3.0 Video Renderer I wrote -- Media Player .NET (MPDN). The reason I'm doing this is because I know what my code does intimately and how it should work.
Let's get onto testing the cards then. Both cards were tested with the MPDN default settings on a 1280x1024 monitor at 50Hz. The NVIDIA card ran without any issues (render time of ~19ms). The AMD card however, kept causing Windows 7 to complain "Windows has detected that your computer's performance is slow" and if MPDN kept on playing, Windows reverted back to the basic colour scheme (turned off Aero mode). Turning on MPDN's on-screen player stats, it was immediately obvious: render and present times were all over the place! However, once full screen exclusive mode was activated, render time immediately settled at ~10ms.
I was baffled. As it turns out, AMD drivers have a problem with 50Hz monitors. Even without running MPDN, you could see Windows 7 DWM dropping frames as you move just a Windows Explorer window (it was visibly jerky)! I then switched the monitor to 60Hz to see if it exhibits the same problem -- Not at all! At 60Hz, it ran fine, mostly. Occasionally render and present times still shot up and caused MPDN to drop frames (which did not happen on the NVIDIA card), but it mostly ran fine.
Without spending more time into my investigations (although I did ran several other versions of legacy drivers from 12.11 HotFix to 13.1 modded ones to no avail), I'll have to point my fingers at AMD. Among the three major GPU vendors, AMD have the worst drivers. Yes, Intel is one of the three vendors and they have much better drivers than AMD! Oh how the tides have turned in recent years!
I have no evidence to suggest that this bug affects all of the AMD HD 4000 series GPUs but given they were based of the foundation chip RV770, I would not be surprised if the entire line suffers from this very bug. Furthermore, with AMD's track record (i.e. absolute disinterest) in fixing bugs in their legacy drivers (and even drivers for their latest GPUs), it is likely that this will never get fixed.
On my test PC, the Catalyst drivers face an even more daunting task - they need to get the graphics card to coexist with an Intel GPU (i.e. Main monitor is hooked up to the Intel GPU while a secondary monitor is hooked up to the AMD card). This particular setup worked beautifully with the NVIDIA 8400GS. With the AMD HD 4350, however, it would always cause Windows 7 to revert to basic colour scheme when you have it render the frames but present it on another GPU (i.e. rendering is done on the AMD GPU and then gets presented on the Intel GPU in windowed mode). On the other hand, both Intel and NVIDIA drivers worked well either directions (rendering on Intel, present on NVIDIA and vice versa).
This particular setup cannot be considered unorthodox in this day and age. Unfortunately, AMD cannot seem to get their drivers to work properly under any circumstances besides the monitor refresh rate set at 60Hz and on a single GPU setup. You have been warned: Deviate at your own peril.
Conclusion
While the AMD HD 4350 card is definitely a superior card to the NVIDIA 8400GS, it suffers from abysmal driver quality. This makes it completely useless as a HTPC card where you would want to set your TV frequency to match the video being played. In the recent releases of MPDN, the AMD card is also exhibiting artefacts running PixelShader code that both Intel and NVIDIA GPUs have no problems running. I have yet to investigate into this issue so this will be an article for another day. Given my experience as a software developer, I would stay away from AMD graphics cards if I were you.
Thursday, June 27, 2013
JMicron JMB36x RAID Status Monitor
I recently worked on a project that requires scheduled status monitoring of a RAID1 (mirrored) volume facilitated via the inexpensive JMicron JMB36x chipset.
To my disbelief, JMicron's xRaidSetup (the facility to create RAID volumes) does not have the ability to report RAID status via email notification which other brands such as Marvell do (I believe Silicon Image as well). So, I had to do it the hard way - reverse engineer xRaidSetup.exe and painstakingly via dis-assembly figure out what it does to get a RAID volume's status (all I wanted to know was if it's running normally!).
I've created xRaidChecker (download) for those who needed the same feature. It's a console application that returns a number indicating the RAID status of the first RAID volume (currently only supports one volume).
Return value of 1 indicates volume is running normally. Any other values indicate an 'Abnormal' status according to xRaidSetup.exe. I'm convinced, however, that there must be specific values that indicate statuses such as 'Rebuild Required' and 'Rebuilding'. If you encounter a return value other than 1, do find out what it means and let me know.
p.s. xRaidChecker needs to be run in elevated command prompt (run as Administrator), or, as I've got it set up, via Task Scheduler running with System privileges and sending out email notifications via a batch file.
p.p.s. JMicron's xRaidSetup must already be installed and your RAID volume set up before you run xRaidChecker (it uses xRaidAPI.dll).
To my disbelief, JMicron's xRaidSetup (the facility to create RAID volumes) does not have the ability to report RAID status via email notification which other brands such as Marvell do (I believe Silicon Image as well). So, I had to do it the hard way - reverse engineer xRaidSetup.exe and painstakingly via dis-assembly figure out what it does to get a RAID volume's status (all I wanted to know was if it's running normally!).
I've created xRaidChecker (download) for those who needed the same feature. It's a console application that returns a number indicating the RAID status of the first RAID volume (currently only supports one volume).
Return value of 1 indicates volume is running normally. Any other values indicate an 'Abnormal' status according to xRaidSetup.exe. I'm convinced, however, that there must be specific values that indicate statuses such as 'Rebuild Required' and 'Rebuilding'. If you encounter a return value other than 1, do find out what it means and let me know.
p.s. xRaidChecker needs to be run in elevated command prompt (run as Administrator), or, as I've got it set up, via Task Scheduler running with System privileges and sending out email notifications via a batch file.
p.p.s. JMicron's xRaidSetup must already be installed and your RAID volume set up before you run xRaidChecker (it uses xRaidAPI.dll).
Wednesday, February 20, 2013
Building ICU (ICU4C) on Cygwin
Now that MCP relies on ICU 50 for its String class (and likely other globalization related classes in the future), we need to build and install ICU first in order to get MCP to compile on Cygwin.
For some reason, the default build instructions does not work. Make will error out (-f pkgdataMakefile is unrecognized by /bin/sh). The problem is with ICU's runConfigureICU script which doesn't properly configure compiler / linker / make flags for Cygwin. Worse, if you follow the instructions and ran runConfigureICU Cygwin, there will be more errors you'll have to deal with.
This is what I had to do instead:
runConfigureICU Linux
export MAKE=make
Notice the first line after you run runConfigureICU Linux. It exports CC, CXX, CFLAGS and CXXFLAGS appropriately. The runConfigureICU Cygwin version however does not. All that the former was missing was a MAKE export. Once you've done that, you can go ahead and make.
For some reason, the default build instructions does not work. Make will error out (-f pkgdataMakefile is unrecognized by /bin/sh). The problem is with ICU's runConfigureICU script which doesn't properly configure compiler / linker / make flags for Cygwin. Worse, if you follow the instructions and ran runConfigureICU Cygwin, there will be more errors you'll have to deal with.
This is what I had to do instead:
runConfigureICU Linux
export MAKE=make
Notice the first line after you run runConfigureICU Linux. It exports CC, CXX, CFLAGS and CXXFLAGS appropriately. The runConfigureICU Cygwin version however does not. All that the former was missing was a MAKE export. Once you've done that, you can go ahead and make.
Tuesday, November 20, 2012
Introducing Managed C++ for GCC
I was not particularly impressed with Boost's hack of getting C++ to have some sort of automatic memory management via boost::shared_ptr. Not only does it suffer from circular references, its handling of 'this' pointer is also dismally complicated especially for classes with multiple inheritance. Yes, there may be solutions out there for these common boost problems, **but** it should not have been a problem to begin with!
Two years ago, I created a .NET like framework for C++ Builder with precise GC and found it to be a lot more straight forward to use compared to Boost. Ironically, C++ is actually better suited to a precise garbage collector than it is to smart pointers. For example, have you inadvertently called shared_from_this() (indirectly, of course) from a class' constructor? This is just another one of many pesky pitfalls C++ programmers have to constantly remind themselves. Isn't there enough pitfalls in the highly ambiguous language already? With sequence points, most vexing parse and whatnot, the C++ language itself is already too complicated for its own good. Herb Sutter certainly thought it's a good idea to add another layer of complexity to that by championing Boost.
Sure, Boost is much more than just shared_ptr. In fact, I intend to make this Managed C++ framework completely compatible with Boost, replacing all the various different boost pointers (e.g. shared_ptr, intrusive_ptr, unique_ptr/auto_ptr, scoped_ptr, shared_array, scoped_array, weak_ptr) with their GC counterparts and dropping most of the nonsense along the way. We only need 2 types of GC pointers -- gc_ptr and gc_array -- along with a WeakReference class for weak_ptr replacement.
In my future blogs, I'll explain more about the unnecessary complexities added by Boost's smart pointer and how gc_ptr and gc_array transparently and naturally avoid all these complexities.
In the meantime, I have released MCP -- Managed C++ for GCC under the GPLv3 license. Head to the MCP website on SourceForge for more information.
Two years ago, I created a .NET like framework for C++ Builder with precise GC and found it to be a lot more straight forward to use compared to Boost. Ironically, C++ is actually better suited to a precise garbage collector than it is to smart pointers. For example, have you inadvertently called shared_from_this() (indirectly, of course) from a class' constructor? This is just another one of many pesky pitfalls C++ programmers have to constantly remind themselves. Isn't there enough pitfalls in the highly ambiguous language already? With sequence points, most vexing parse and whatnot, the C++ language itself is already too complicated for its own good. Herb Sutter certainly thought it's a good idea to add another layer of complexity to that by championing Boost.
Sure, Boost is much more than just shared_ptr. In fact, I intend to make this Managed C++ framework completely compatible with Boost, replacing all the various different boost pointers (e.g. shared_ptr, intrusive_ptr, unique_ptr/auto_ptr, scoped_ptr, shared_array, scoped_array, weak_ptr) with their GC counterparts and dropping most of the nonsense along the way. We only need 2 types of GC pointers -- gc_ptr and gc_array -- along with a WeakReference class for weak_ptr replacement.
In my future blogs, I'll explain more about the unnecessary complexities added by Boost's smart pointer and how gc_ptr and gc_array transparently and naturally avoid all these complexities.
In the meantime, I have released MCP -- Managed C++ for GCC under the GPLv3 license. Head to the MCP website on SourceForge for more information.
Tuesday, October 23, 2012
Building Cygwin GCC 4.5.3 with --enable-plugin
Many people have tried building GCC 4.5.3 on Cygwin with the configure flag of --enable-plugin only to find that make subsequently fails with the following errors.
checking for -rdynamic... objdump: conftest: not a dynamic object no
checking for library containing dlopen... none required
checking for -fPIC -shared... no
configure: error:
Building GCC with plugin support requires a host that supports
-fPIC, -shared, -ldl and -rdynamic.
make[1]: *** [configure-gcc] Error 1
It appears that GCC would not build with --enable-plugin on Cygwin as -rdynamic and -fPIC are not applicable for a Windows PE.
Why would it need -rdynamic and -fPIC? I honestly thought those requirements are purely artificial as it would be absolutely possible to create a DLL under Windows and there is no reason why GCC can't use it.
So I set about finding out how this could be done and eventually found two articles [1][2] that allowed me to get to a working solution. I've combined the two articles to create these procedures.
Note: Start the following steps from a directory where you will have all your GCC files location in it.
1) Download and extract helper files I've put together which you'll be using later.
# obtain Cygwin GCC Plugin helper files
wget http://www.zachsaw.com/downloads/cygwin_gcc_plugin/cygwin_gcc_plugin_files.tar.bz2
tar -jxvf cygwin_gcc_plugin_files.tar.bz2
2) Run the following commands
# obtain GCC 4.5.3 (see http://gcc.gnu.org/mirrors.html for alternate mirrors)
wget http://www.netgull.com/gcc/releases/gcc-4.5.3/gcc-4.5.3.tar.bz2
tar -jxvf gcc-4.5.3.tar.bz2
# apply patches
cd gcc-4.5.3
patch -p0 < ../cygwin_gcc_plugin/finish_decl.diff
patch -p0 < ../cygwin_gcc_plugin/cygwin_enable_plugin.diff
patch -p0 < ../cygwin_gcc_plugin/cygwin_enable_plugin_cc1.diff
patch -p0 < ../cygwin_gcc_plugin/cygwin_enable_plugin_cc1plus.diff
# build GCC
cd ..
mkdir gcc-objdir
mkdir gcc-dist
cd gcc-objdir
../gcc-4.5.3/configure --disable-bootstrap --enable-version-specific-runtime-libs --enable-static --enable-shared --enable-shared-libgcc --disable-__cxa_atexit --with-dwarf2 --disable-sjlj-exceptions --enable-languages=c,c++,lto --enable-lto --enable-libssp --enable-plugin --enable-threads=posix --prefix=$PWD/../gcc-dist
make
make install
cd ..
*** make took 2 hours on my machine!
3) Create symlink for g++-plugin and gcc-plugin in /usr/bin to point to the newly built g++ and gcc respectively.
4) Set environment vars for $GCC_PLUGIN_DIR and $builtgcc.
export GCC_PLUGIN_DIR=`g++-plugin -print-file-name=plugin`
export builtgcc=<path>/gcc-objdir
5) Generate import libraries.
mkdir $GCC_PLUGIN_DIR/lib
cygwin_gcc_plugin/lazyimp.pl $GCC_PLUGIN_DIR/lib/libcc1.a $builtgcc/gcc/cc1.def
cygwin_gcc_plugin/lazyimp.pl $GCC_PLUGIN_DIR/lib/libcc1plus.a $builtgcc/gcc/cc1plus.def
This will take some time.
6) Compile dll.c and archive it into libcc1.a and libcc1plus.a
gcc-plugin -O3 -Wall cygwin_gcc_plugin/dll.c -c
ar rcs $GCC_PLUGIN_DIR/lib/libcc1.a dll.o
ar rcs $GCC_PLUGIN_DIR/lib/libcc1plus.a dll.o
7) You now have both libcc1.a (for C) and libcc1plus.a (for C++) that you can link to when you build your gcc plugin.
To build a plugin:
g++-plugin -c -I`g++-plugin -print-file-name=plugin`/include main.cpp
g++-plugin -fPIC -shared -Wl,-e,_lazymain@12 -L`g++-plugin -print-file-name=plugin`/lib -o plugin.dll main.o -lcc1plus
Or one step build and link:
g++-plugin -shared -Wl,-e,_lazymain@12 -I`g++-plugin -print-file-name=plugin`/include -L`g++-plugin -print-file-name=plugin`/lib -o plugin.dll main.cpp -lcc1plus
Test the plugin:
g++-plugin -S -fplugin=./plugin.dll test.cpp
checking for -rdynamic... objdump: conftest: not a dynamic object no
checking for library containing dlopen... none required
checking for -fPIC -shared... no
configure: error:
Building GCC with plugin support requires a host that supports
-fPIC, -shared, -ldl and -rdynamic.
make[1]: *** [configure-gcc] Error 1
It appears that GCC would not build with --enable-plugin on Cygwin as -rdynamic and -fPIC are not applicable for a Windows PE.
Why would it need -rdynamic and -fPIC? I honestly thought those requirements are purely artificial as it would be absolutely possible to create a DLL under Windows and there is no reason why GCC can't use it.
So I set about finding out how this could be done and eventually found two articles [1][2] that allowed me to get to a working solution. I've combined the two articles to create these procedures.
Note: Start the following steps from a directory where you will have all your GCC files location in it.
1) Download and extract helper files I've put together which you'll be using later.
# obtain Cygwin GCC Plugin helper files
wget http://www.zachsaw.com/downloads/cygwin_gcc_plugin/cygwin_gcc_plugin_files.tar.bz2
tar -jxvf cygwin_gcc_plugin_files.tar.bz2
2) Run the following commands
# obtain GCC 4.5.3 (see http://gcc.gnu.org/mirrors.html for alternate mirrors)
wget http://www.netgull.com/gcc/releases/gcc-4.5.3/gcc-4.5.3.tar.bz2
tar -jxvf gcc-4.5.3.tar.bz2
# apply patches
cd gcc-4.5.3
patch -p0 < ../cygwin_gcc_plugin/finish_decl.diff
patch -p0 < ../cygwin_gcc_plugin/cygwin_enable_plugin.diff
patch -p0 < ../cygwin_gcc_plugin/cygwin_enable_plugin_cc1.diff
patch -p0 < ../cygwin_gcc_plugin/cygwin_enable_plugin_cc1plus.diff
cd ..
mkdir gcc-objdir
mkdir gcc-dist
cd gcc-objdir
../gcc-4.5.3/configure --disable-bootstrap --enable-version-specific-runtime-libs --enable-static --enable-shared --enable-shared-libgcc --disable-__cxa_atexit --with-dwarf2 --disable-sjlj-exceptions --enable-languages=c,c++,lto --enable-lto --enable-libssp --enable-plugin --enable-threads=posix --prefix=$PWD/../gcc-dist
make
make install
cd ..
*** make took 2 hours on my machine!
3) Create symlink for g++-plugin and gcc-plugin in /usr/bin to point to the newly built g++ and gcc respectively.
4) Set environment vars for $GCC_PLUGIN_DIR and $builtgcc.
export GCC_PLUGIN_DIR=`g++-plugin -print-file-name=plugin`
export builtgcc=<path>
5) Generate import libraries.
mkdir $GCC_PLUGIN_DIR/lib
cygwin_gcc_plugin/lazyimp.pl $GCC_PLUGIN_DIR/lib/libcc1.a $builtgcc/gcc/cc1.def
cygwin_gcc_plugin/lazyimp.pl $GCC_PLUGIN_DIR/lib/libcc1plus.a $builtgcc/gcc/cc1plus.def
This will take some time.
6) Compile dll.c and archive it into libcc1.a and libcc1plus.a
gcc-plugin -O3 -Wall cygwin_gcc_plugin/dll.c -c
ar rcs $GCC_PLUGIN_DIR/lib/libcc1.a dll.o
ar rcs $GCC_PLUGIN_DIR/lib/libcc1plus.a dll.o
To build a plugin:
g++-plugin -c -I`g++-plugin -print-file-name=plugin`/include main.cpp
g++-plugin -fPIC -shared -Wl,-e,_lazymain@12 -L`g++-plugin -print-file-name=plugin`/lib -o plugin.dll main.o -lcc1plus
Or one step build and link:
g++-plugin -shared -Wl,-e,_lazymain@12 -I`g++-plugin -print-file-name=plugin`/include -L`g++-plugin -print-file-name=plugin`/lib -o plugin.dll main.cpp -lcc1plus
Test the plugin:
g++-plugin -S -fplugin=./plugin.dll test.cpp
Subscribe to:
Posts (Atom)